
Migrating to Databricks helps accelerate innovation, enhance productivity and manage costs better with faster, more efficient infrastructure and DevOps
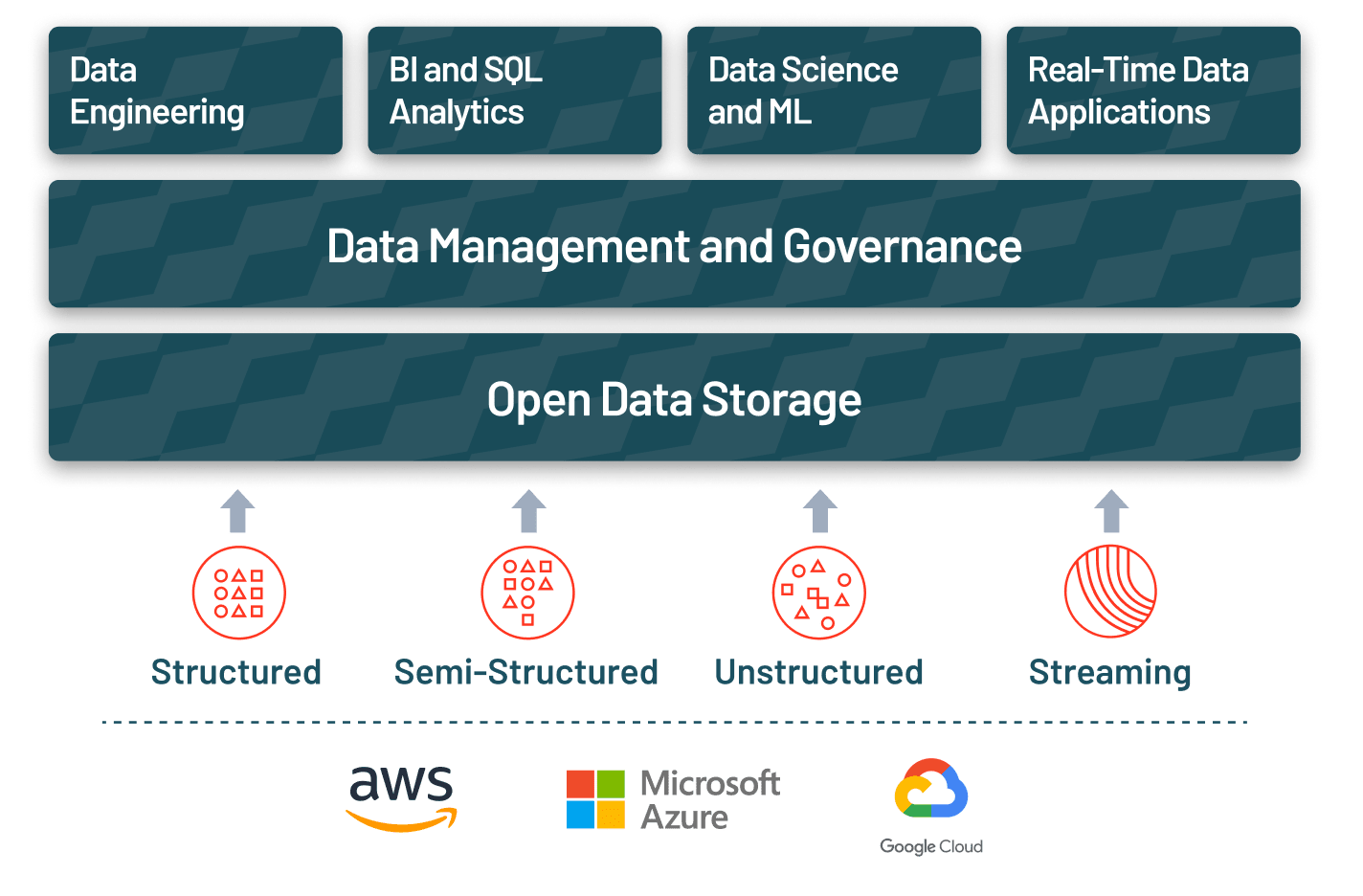
Discover the benefits of migrating from Hadoop to the Databricks Lakehouse Platform — one open, simple platform to store and manage all your data for all your analytics workloads.
While reducing infrastructure and licensing costs is one major advantage, the Databricks Lakehouse Platform takes a lake-first approach to increase the speed and scale to handle all your production analytics and AI use cases — helping you meet your SLAs, streamline operations and improve productivity.

Why Migrate with Databricks?
Forrester TEI Study finds 417% ROI for companies switching to Databricks.
47%
Cost-savings from retiring
legacy infrastructure
Retire legacy infrastructure and adopt an open and elastic cloud-native service that doesn’t require excess capacity or hardware upgrades.
5%
Increase in revenue with
Data-driven innovation
Use all enterprise data to build new data products and increase operational efficiencies with powerful artificial intelligence and machine learning capabilities.
25%
Increase in data team
productivity
Minimize the DevOps burden with a fully-managed, performant and reliable data and analytics platform.
Cloud-based
Build an open, simple and collaborative lakehouse architecture with Databricks
![]()
Cost-effective scale and performance in the cloud
![]()
![]()
Lakehouse
Build an open, simple and collaborative lakehouse architecture with Databricks
![]()
![]()
![]()
![]()
![]()
![]()
Databricks Lakehouse Platform
Simple
Unify your data, analytics, and AI on one common platform for all data use cases
Open
Unify your data ecosystem with open source, standards, and formats
Collaborative
Unify your data teams to collaborate across the entire data and AI workflow
Technology mapping Hadoop to Databricks

(Spark)
(Highly tuned Spark engine: faster, less
compute, one-stop-shop)
(Hive, Impala)
(Highly tuned Spark engine: faster, less
compute, one-stop-shop)
(Storm/Spark)
(Spark Structured Streaming + Delta Lake:
Streaming + Batch ingest)
(MapReduce)
(orders of magnitude faster – but may need
manual work)
(Hbase)
w/Hbase on cloud
(Alternatively: use cloud data stores well
integrated with Databricks)



- As a global CPG company, Reckitt struggled with the complexity of forecasting demand across 500,000 stores
- They process over 2TB of data every day across 250 pipelines
- Hadoop infrastructure proved to be complex, cumbersome and costly to scale. This legacy system also struggled with performance.
- A unified platform for data science, engineering and business analysts to quickly innovate and deliver ML-powered insights
- Delta Lake improved cost optimization and storage space with extreme data compression
- 10x more capacity to support business volume
- 98% data compression from 80TB to 2TB, reducing operational costs
- 2x faster data pipeline performance for 24x7 jobs

- Viacom18 needs to process terabytes of daily viewer data to optimize programming
- Their on-premises Hadoop data lake was unable to process 90 days of rolling data within SLAs, limiting their ability to deliver on business needs
- Azure Databricks provides fully managed autoscale clusters in the cloud that simplify infrastructure management
- Delta Lake caching significantly accelerated query speeds
- Collaborative notebooks with built-in ML libraries enable teams to innovate faster
- Significantly lowered costs with faster query time and less devops despite increasing data volumes
- Improved team productivity by 26% with a fully managed platform that supports ETL, analytics and ML at scale
- Sam’s Club needs to process daily bakery data from all their stories to predict food spoilage.
- They were running 10+ large hadoop clusters, multiple large instances of Teradata and numerous SQL databases.
- This infrastructure was costly, hard to manage and unable to deliver granular daily forecasts in a timely fashion.
- Centralized their data analytics architecture on Azure Databricks
- Delta Lake significantly reduced query speeds compared to legacy Teradata and Hadoop enabling real-time forecasts
- Collaborative workspaces improved productivity across 10+ workspaces, 100+ users, 1000+ notebooks
- Reduced infrastructure costs by $900K
- Fresh processing analysis went from 7 hours to 40 minutes
- 10% reduction in fresh food spoilage due to improved forecast (~$100M/year)
Partner ecosystem

Featured partners


in the cloud
Databricks and StreamSets have partnered
to bring rapid data pipeline design and testing
to critical cloud workloads
Watch now




Migrate your data and your workloads with MLens
Learn more
Ready to get started?
Resources
Blogs & Whitepapers
- It’s Time to Re-evaluate Your Relationship With Hadoop
- Hadoop to Databricks Technical Migration Guide
- Top Considerations When Migrating Off of Hadoop
- 5 Key Steps to Successfully Migrating from Hadoop to the Lakehouse Architecture
- Why Scribd Chose Delta Lake
- Forrester TEI Spotlight – Databricks Lakehouse Platform