
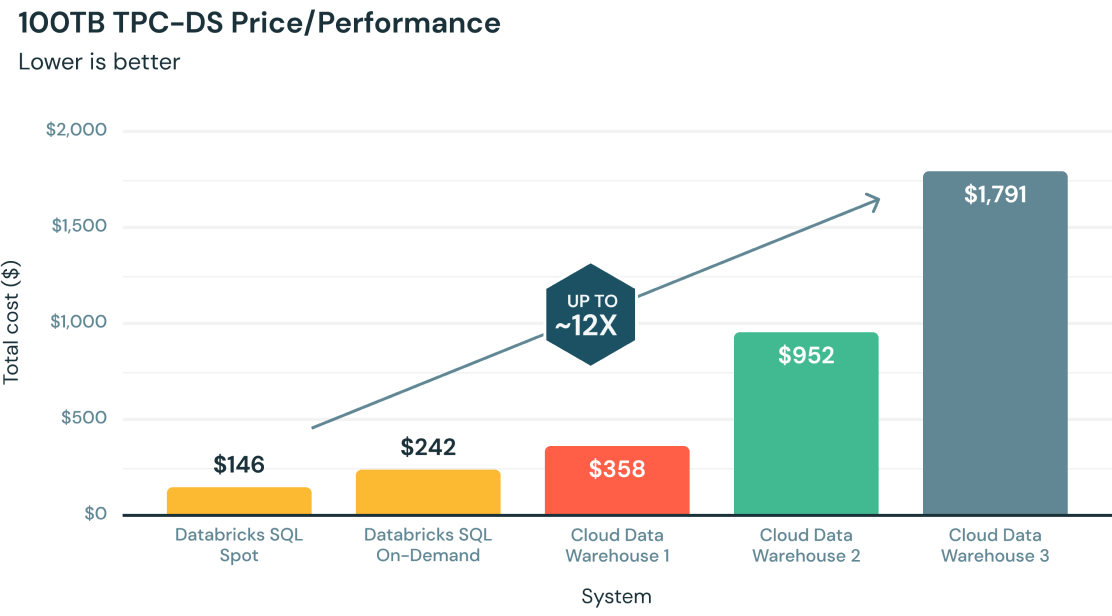
Databricks SQL (DB SQL) allows customers to operate a multicloud lakehouse architecture that provides up to 12x better price/performance than traditional cloud data warehouses. Using open source standards to avoid data lock-in, it provides the reliability, quality and performance that data lakes natively lack.
![]()
Reliable, lightning-fast analytics on data lake data
Gain a competitive edge by running SQL queries on your lakehouse with data warehousing performance at data lake economics. DB SQL brings reliability, quality, security and performance to your data lake to support traditional analytics workloads using your most recent and complete data.
![]()
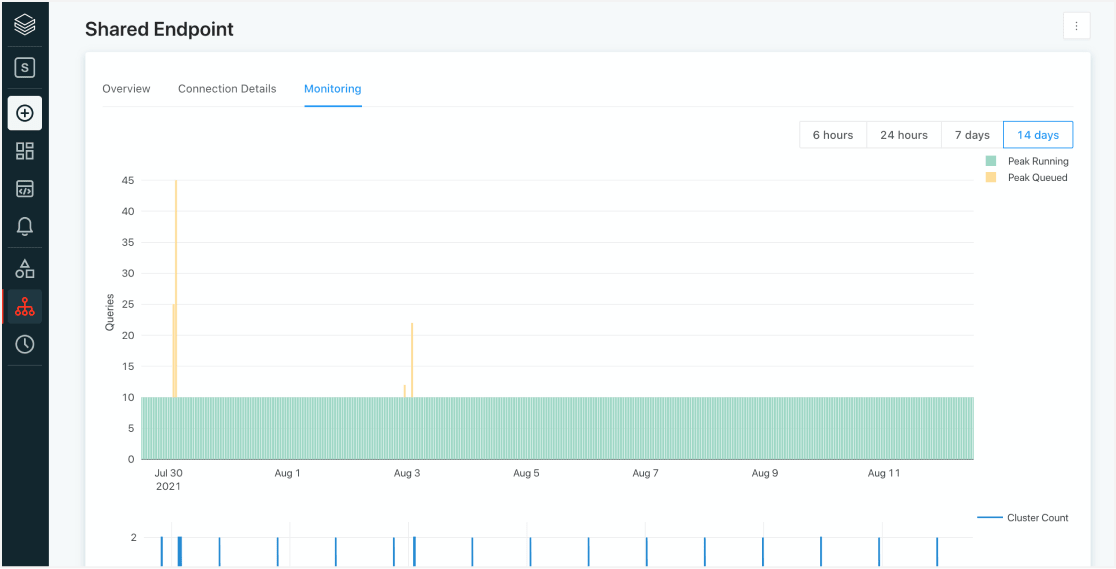
Simplified administration and governance
Quickly setup instant, elastic SQL compute decoupled from storage. Databricks automatically determines instance types and configuration for the best price/performance. Then, easily manage users, data, and resources with endpoint monitoring, query history, and fine-grained governance.
![]()
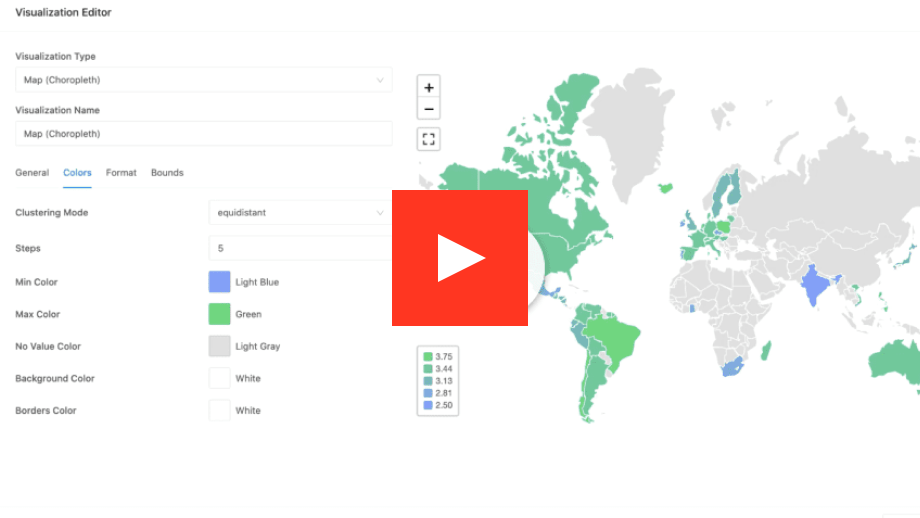
Analytics on all your data with your tools of choice
Leverage your preferred BI tools to analyze the most recent and complete data with world-class performance, without having to move data into a data warehouse. Databricks SQL also empowers every analyst across your organization to quickly find and share new insights with the built-in SQL editor, visualizations and dashboards.

How does it work?
Up to 12x better price/performance for query execution
Databricks SQL is packed with thousands of optimizations to provide you with the best performance for all query types and real-world applications. This includes Photon — the next-generation query engine — which provides up to 12x better price/performance compared to other cloud data warehouses.
Simplified administration and governance for your lakehouse
Databricks SQL makes it easy to set up and manage SQL compute resources, thanks to a central log that records usage across virtual clusters, users and time. This makes it easier to observe workloads across DB SQL, third-party BI tools and any other SQL clients in one place, which in turn helps triage errors and performance issues. Administrators can then drill down into the phases of each query’s execution to troubleshoot problems and support audits.
Connect with your existing tools
Connect your preferred BI tools and benefit from fast performance, low latency and high user concurrency to your data lake data. Setting up reliable connections to your Delta Lake tables is simple, and you can integrate your existing authentication solution. Re-engineered ODBC/JDBC drivers provide lower latency and less overhead to reduce round trips by 0.25 seconds. Data transfer rate is improved 50%, and metadata retrieval operations execute up to 10x faster.
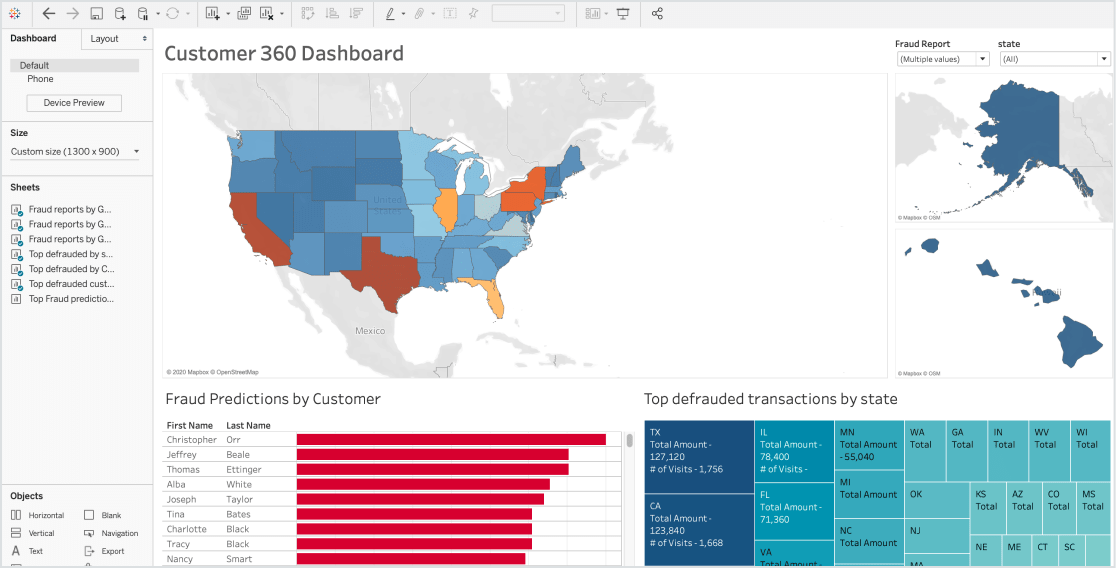
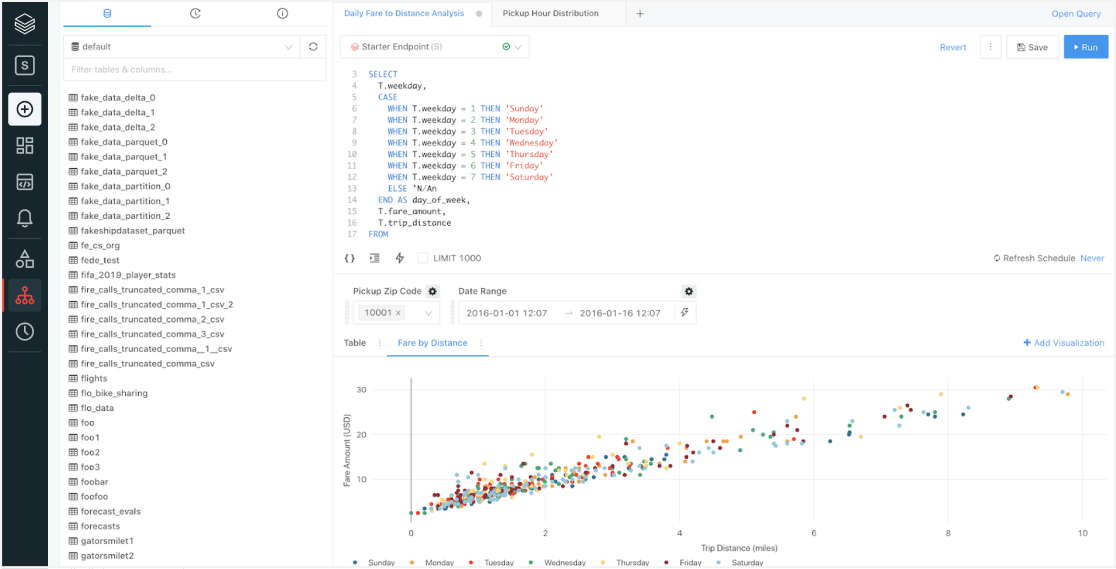
First-class SQL development experience
Databricks SQL allows data analysts to quickly discover and find data sets, write queries in a familiar SQL syntax and easily explore Delta Lake table schemas for ad hoc analysis. Regularly used SQL code can be saved as snippets for quick reuse, and query results can be cached to keep run times short.
Quickly discover and share new insights
Analysts can easily make sense of query results through a wide variety of rich visualizations, and quickly build dashboards with an intuitive drag-and-drop interface. To keep everyone current, dashboards can be shared and configured to automatically refresh, as well as to alert the team to meaningful changes in the data.
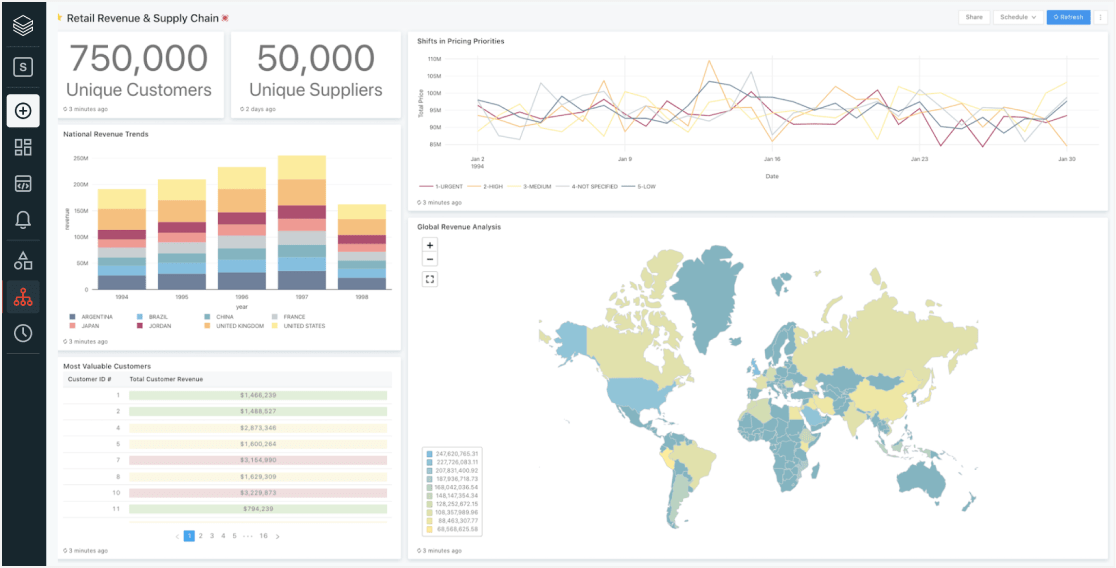
Use cases
![]()
Enable your lakehouse infrastructure
Operate a multicloud lakehouse architecture that provides data warehouse performance at data lake economics. Databricks SQL enables analysts and data scientists to reliably perform SQL queries and BI directly on the freshest and most complete data using their tools of choice — directly on your data lake — while greatly simplifying architectures by reducing the need for more disparate systems.
![]()
Leverage your existing BI tools
Enable business analysts to directly query data lake data using their favorite BI tool and avoid data silos. Re-engineered and optimized connectors ensure fast performance, low latency and high user concurrency to your data lake. Now analysts can use the best tool for the job on one single source of truth for your data.
![]()
Collaboratively explore the freshest data
Enable every analyst and SQL professional in your organization to quickly find and share new insights with a collaborative and self-served analytics experience. Confidently manage data permissions with fine-grained governance, share and reuse queries, and quickly analyze and share results with interactive visualizations and dashboards.
![]()
Build custom data apps
Build rich and custom data-enhanced applications for your own organization or your customers. Benefit from the ease of connectivity, management and better price/performance of DB SQL to simplify development of data-enhanced applications at scale, all served from your data lake.
Integrations
Get critical business data in with one click integrations, and benefit from fast performance, low latency, and high user concurrency for your existing BI tools. Setting up reliable connections to your Delta Lake tables is simple, and you can integrate your existing authentication solution.

+ Any other Apache Spark™️ compatible client
“Now more than ever, organizations need a data strategy that enables speed and agility to be adaptable. As organizations are rapidly moving their data to the cloud, we’re seeing growing interest in doing analytics on the data lake.
The introduction of Databricks SQL delivers an entirely new experience for customers to tap into insights from massive volumes of data with the performance, reliability and scale they need. We’re proud to partner with Databricks to bring that opportunity to life.”
—Francois Ajenstat, Chief Product Officer, Tableau
![]()







Customers
“Shell has been undergoing a digital transformation as part of our ambition to deliver more and cleaner energy solutions. As part of this, we have been investing heavily in our data lake architecture. Our ambition has been to enable our data teams to rapidly query our massive data sets in the simplest possible way. The ability to execute rapid queries on petabyte-scale data sets using standard BI tools is a game changer for us. Our co-innovation approach with Databricks has allowed us to influence the product roadmap, and we are excited to see this come to market.”
— Dan Jeavons, General Manager — Data Science, Shell
“At Atlassian, we need to ensure teams can collaborate well across functions to achieve constantly evolving goals. A simplified lakehouse architecture would empower us to ingest high volumes of user data and run the analytics necessary to better predict customer needs and improve the experience of our customers.
A single, easy-to-use cloud analytics platform allows us to rapidly improve and build new collaboration tools based on actionable insights.”
— Rohan Dhupelia, Data Platform Senior Manager, Atlassian
“At Wejo, we’re collecting data from more than 50 million accessible connected cars to build a better driving experience.
Databricks and a robust lakehouse architecture will allow us to provide automated analytics to our customers, empowering them to glean insights on nearly 5 trillion data points per month, all in a streaming environment from car to marketplace in seconds.”
— Daniel Tibble, Head of Data, Wejo
“As a company focused on providing data-driven research to our customers, the massive amount of data in our data lake is our lifeblood. By leveraging Databricks and Delta Lake, we have already been able to democratize data at scale, while lowering the cost of running production workloads by 60%, saving us millions of dollars.
We’re excited to build on this momentum by leveraging the Databricks lakehouse architecture that will further empower everyone across our organization — from research analysts to data scientists — to interchangeably use the same data, helping us to provide innovative insights to our customers faster than ever before.”
— Steve Pulec, Chief Technology Officer, YipitData