
Databricks Labs
Databricks Labs are projects created by the field
to help customers get their use cases into production faster!
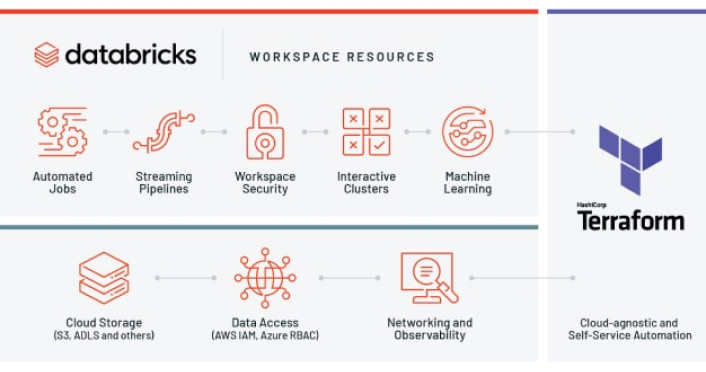
Terraform Integration
You can use the Databricks Terraform provider to manage your Databricks workspaces and the associated cloud infrastructure using a flexible, powerful tool. Databricks customers are using the Databricks Terraform provider to deploy and manage clusters and jobs, provision Databricks workspaces, and configure data access.

DBX
This tool simplifies jobs launch and deployment process across multiple environments. It also helps to package your project and deliver it to your Databricks environment in a versioned fashion. Designed in a CLI-first manner, it is built to be actively used both inside CI/CD pipelines and as a part of local tooling for fast prototyping.
Tempo
The purpose of this project is to provide an API for manipulating time series on top of Apache Spark. Functionality includes featurization using lagged time values, rolling statistics (mean, avg, sum, count, etc), AS OF joins, and downsampling & interpolation. This has been tested on TB-scale of historical data.
Other Projects
Overwatch
Analyze all of your jobs and clusters across all of your workspaces to quickly identify where you can make the biggest adjustments for performance gains and cost savings.
JupyterLab Integration
This package allows to connect to a remote Databricks cluster from a locally running JupyterLab.
Splunk Integration
Add-on for Splunk, an app, that allows Splunk Enterprise and Splunk Cloud users to run queries and execute actions, such as running notebooks and jobs, in Databricks.
Smolder
Smolder provides an Apache Spark™ SQL data source for loading EHR data from HL7v2 message formats. Additionally, Smolder provides helper functions that can be used on a Spark SQL DataFrame to parse HL7 message text, and to extract segments, fields, and subfields, from a message.
Geoscan
Apache Spark ML Estimator for Density-based spatial clustering based on Hexagonal Hierarchical Spatial Indices.
AutoML Toolkit
Toolkit for Apache Spark ML for Feature clean-up, feature Importance calculation suite, Information Gain selection, Distributed SMOTE, Model selection and training, Hyper parameter optimization and selection, Model interprability.
Github Sources →
Learn more:
Broad AutoML Blog
AutoML Toolkit Blog Default Loan Predictions
Family Runner Pipeline API Blog
Feature Factory
An accelerator providing APIs built on top of PySpark with optimization, validation, and deduplication in mind to simplify and unify feature engineering workflow.
Dataframe Rules Engine
Scala Dataframe data quality expectation validation library.
Migrate
Tool to help customers migrate artifacts between Databricks workspaces. This allows customers to export configurations and code artifacts as a backup or as part of a migration between a different workspace.
Github Sources →
Learn more: AWS | Azure
Databricks Sync
A tool used to synchronize source Databricks deployment with a target Databricks deployment.
CICD Templates
cookiecutter project template for automated Databricks CI/CD pipeline creation and deployment.
Data Generator
Generate relevant data quickly for your projects. The Databricks data generator can be used to generate large simulated / synthetic data sets for test, POCs, and other uses
Please note that all projects in the http://github.com/databrickslabs account are provided for your exploration only, and are not formally supported by Databricks with Service Level Agreements (SLAs). They are provided AS-IS and we do not make any guarantees of any kind. Please do not submit a support ticket relating to any issues arising from the use of these projects. Any issues discovered through the use of this project should be filed as GitHub Issues on the Repo. They will be reviewed as time permits, but there are no formal SLAs for support.