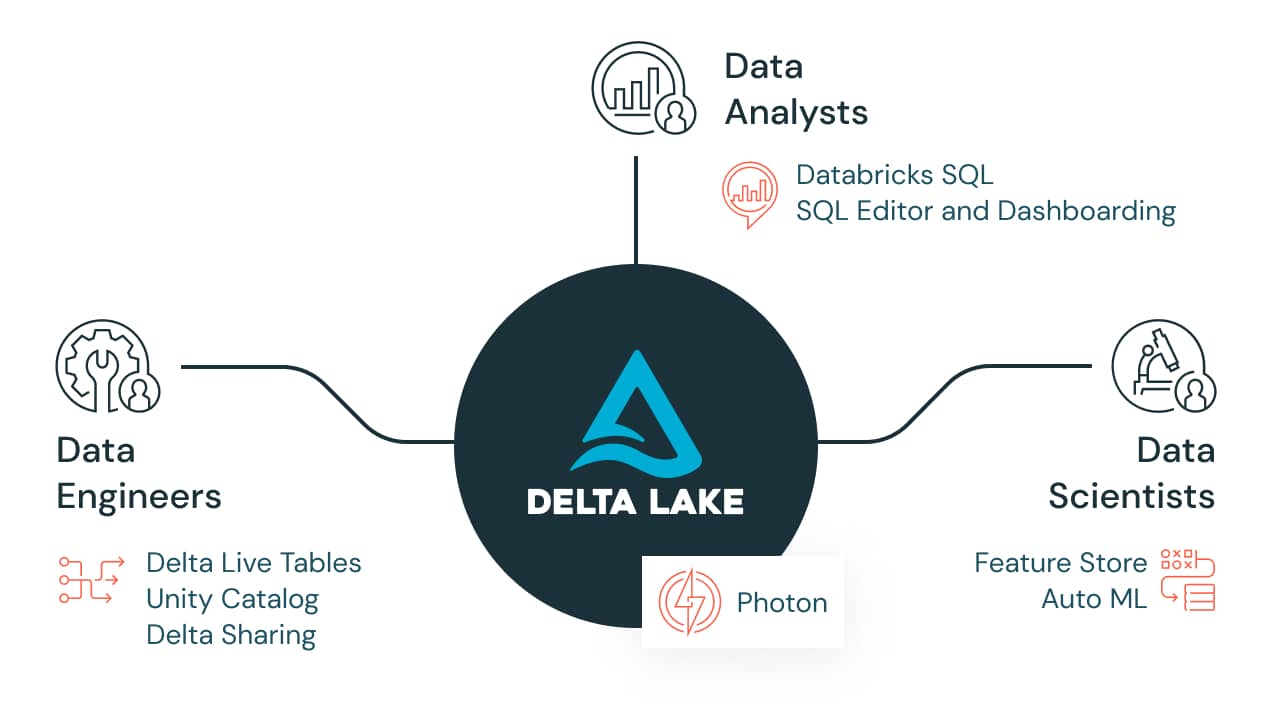
Dive deeper into data engineering on Databricks
Data Ingestion | Data Management | ETL | Data Sharing | Data Governance
Streamline data ingestion into your lakehouse
Incrementally process new files as they land on cloud storage — with no need to manage state information — in scheduled or continuous jobs. Efficiently track new files (with the ability to scale to billions of files) without having to list them in a directory. Databricks automatically infers the schema from the source data and evolves it as the data loads into the Delta Lake lakehouse.
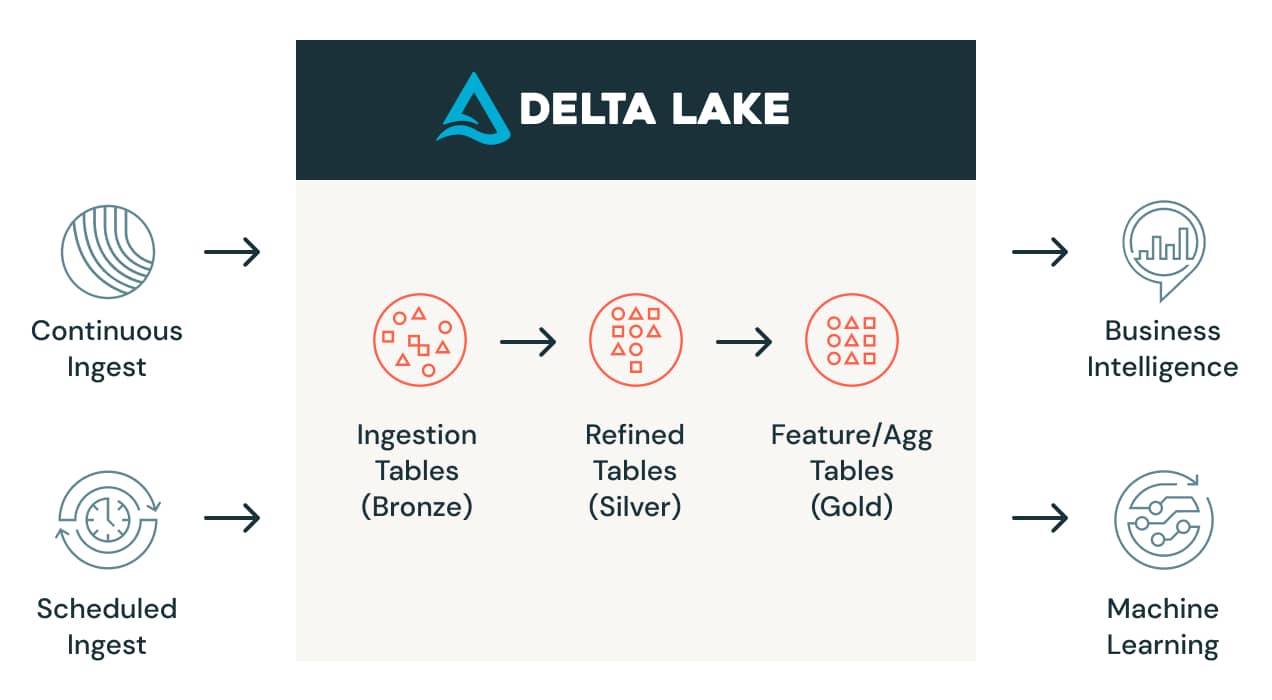
Automate data transformation and processing
Once data is ingested into the lakehouse, data engineers need to turn raw data into structured data ready for analytics, data science or machine learning. Simplify data transformation with Delta Live Tables (DLT) — an easy way to build and manage data pipelines for fresh, high-quality data on Delta Lake. DLT helps data engineering teams by simplifying ETL development and management with declarative pipeline development, improved data reliability and cloud-scale production operations to help build the lakehouse foundation.
Build reliability and quality into your pipelines
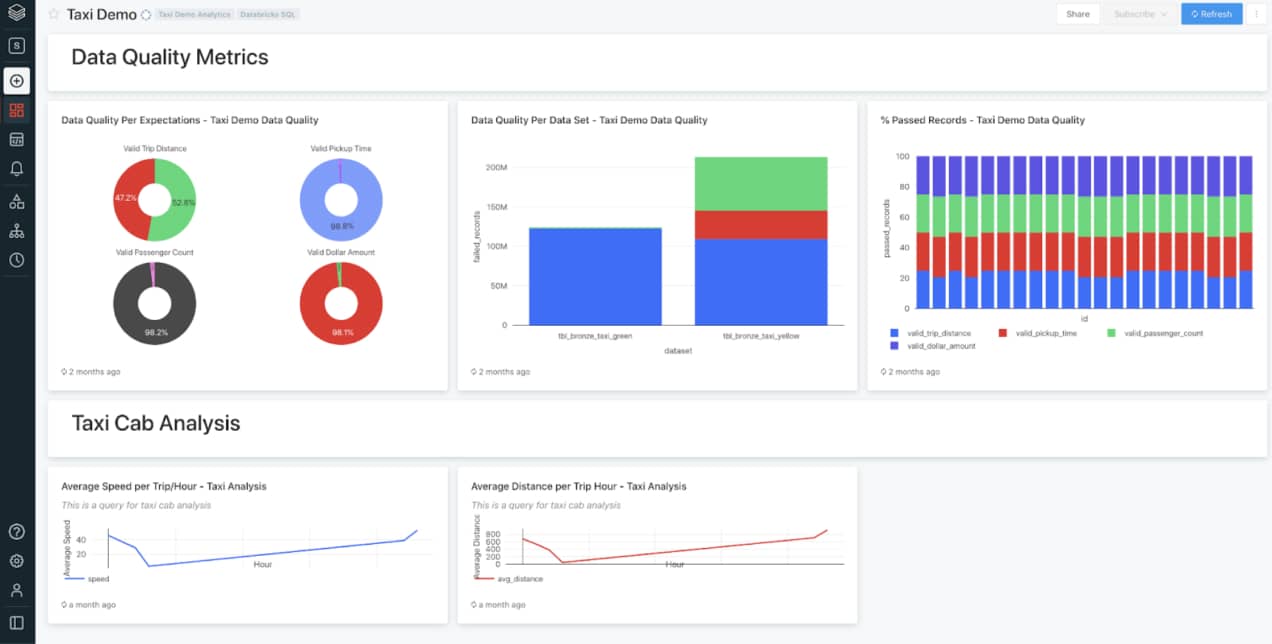
Data quality and integrity are essential for ensuring the overall consistency of the data within the lakehouse for accurate and useful BI, data science and machine learning. With the ability to define and enforce data quality through predefined error policies (fail, drop, alert or quarantine data) and validation and integrity checks, you can prevent bad data from flowing into tables and avoid data quality errors before they impact your business. In addition, you can monitor data quality trends over time to get insight into how data is evolving and where changes may be necessary. These built-in quality controls and schema enforcement tools on Delta Lake save data engineering teams immense amounts of time and energy in error handling and recovery. And since Databricks builds on top of Apache Spark™, data engineers are able to build highly reliable and performant data pipelines that support production data science at massive scale.
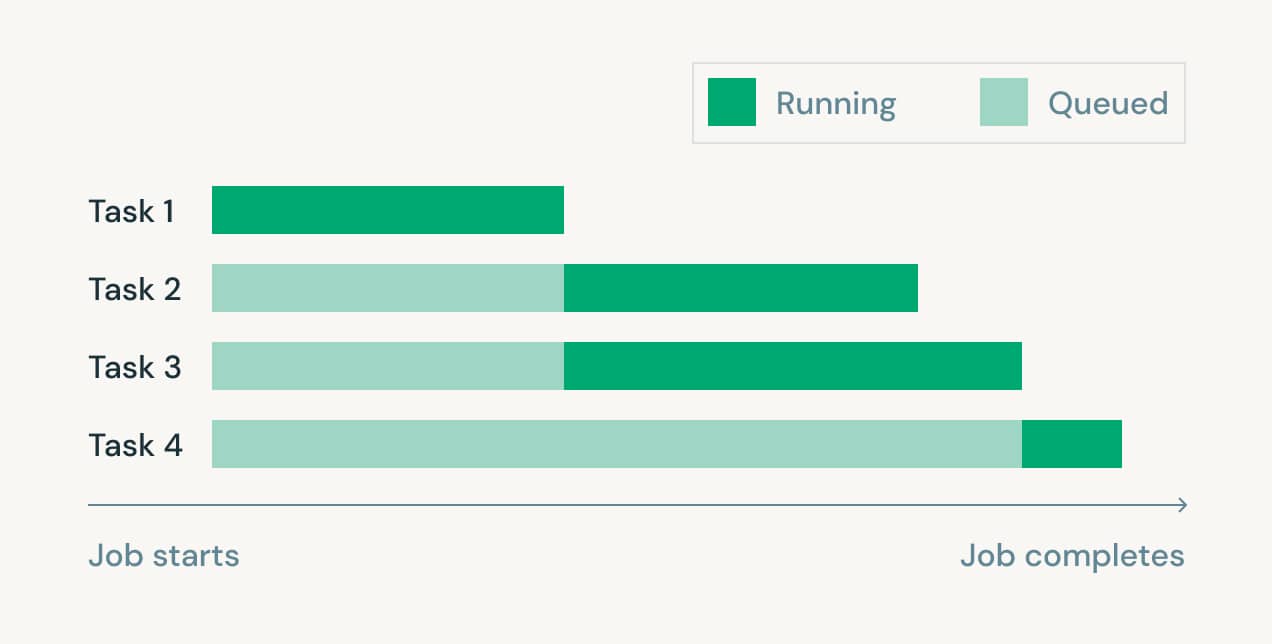
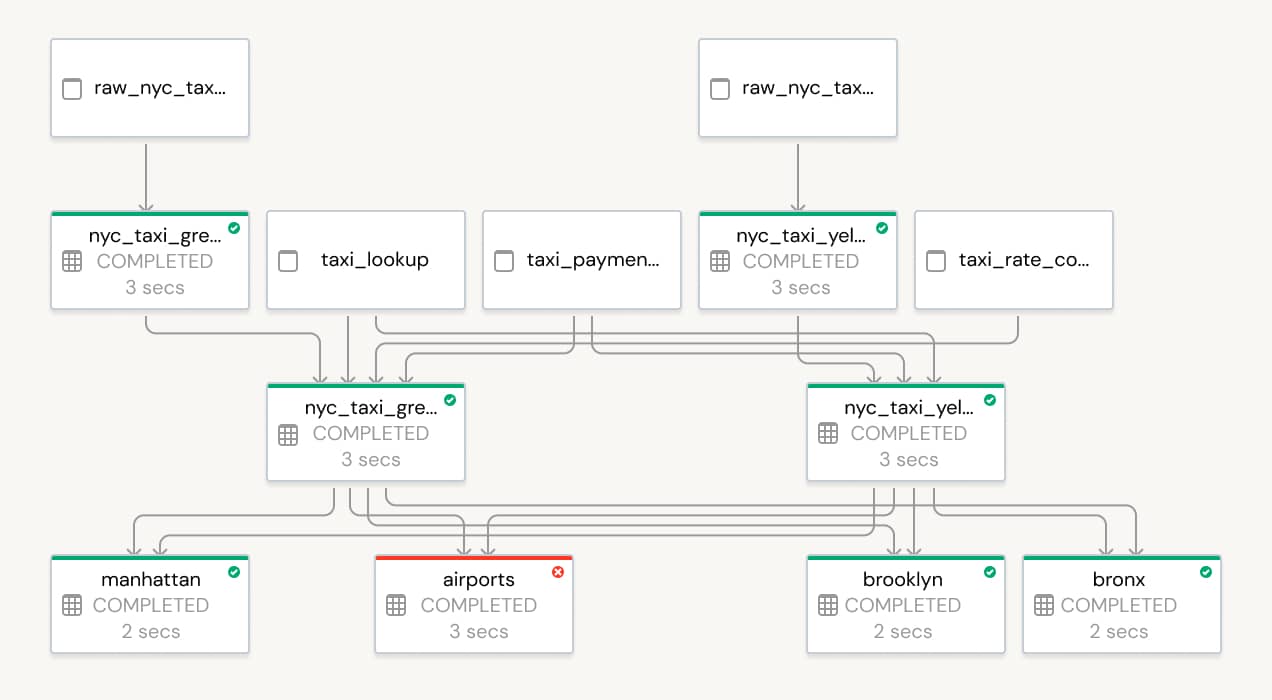
Easily orchestrate pipelines
Schedule DLT pipelines with Databricks Jobs to enable automated full support for end-to-end production-ready pipelines with multiple tasks. Databricks Jobs includes a scheduler that allows data engineers to specify a scheduled time for their ETL workloads and to set up notifications that tell them whether a job ran successfully.
Learn more
Collaborate with data scientists and architects
Once data is ingested and processed, data engineers can unlock its value by enabling every user in the organization to access and collaborate on data in real time. With tools for accessing and using data, sharing data sets, forecasts, models and notebooks, and ensuring a reliable single source of truth, data engineers can better ensure consistency and reliability across all workloads — as well as collaborate better with the data analysts, data scientists and data stewards that use the data.