Elastic Scalability
Optimized for speed, reliability, and scalability for all workloads
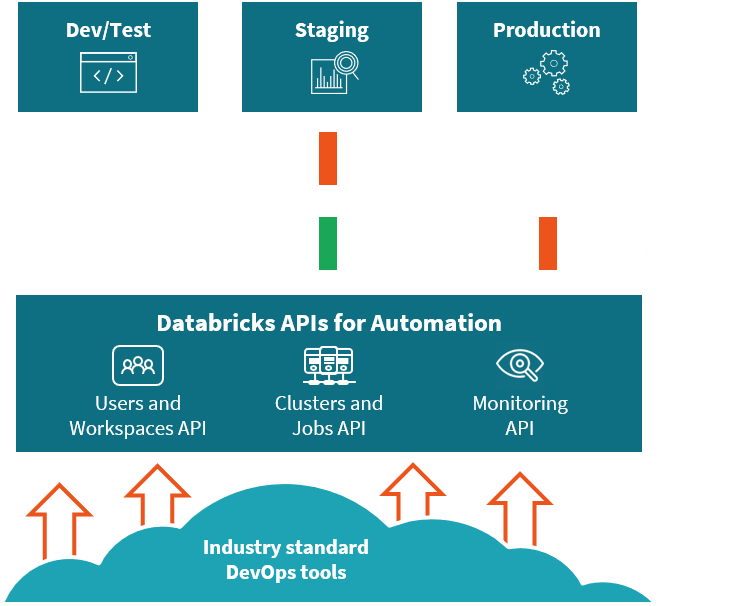
Take data applications from development to production faster using pre-configured data environments and APIs for automation. Streamline operations with autoscaling infrastructure and monitoring.
Benefits for DevOps Teams
FULLY CONFIGURED DATA ENVIRONMENTS
Enable your data teams to deliver value quickly with ready-to-use data environments configured with infrastructure, tools, libraries, users and governance policies
PRODUCTIONIZE FASTER WITH AUTOMATION
APIs for everything from version control, workspace provisioning, user management, clusters, and jobs to ML model management and tracking, allow DevOps teams to automate the data and ML lifecycle.
STREAMLINE OPERATIONS
Use on-demand autoscaling infrastructure and integrations for real-time monitoring to streamline operations in production. Improve performance and reduce downtime of your data pipelines and ML applications.
Features
FULLY CONFIGURED ENVIRONMENTS
Workspaces API: Workspace organizes objects (notebooks, libraries, and experiments) into folders. The API gives the account owner the ability to create team workspaces at scale.
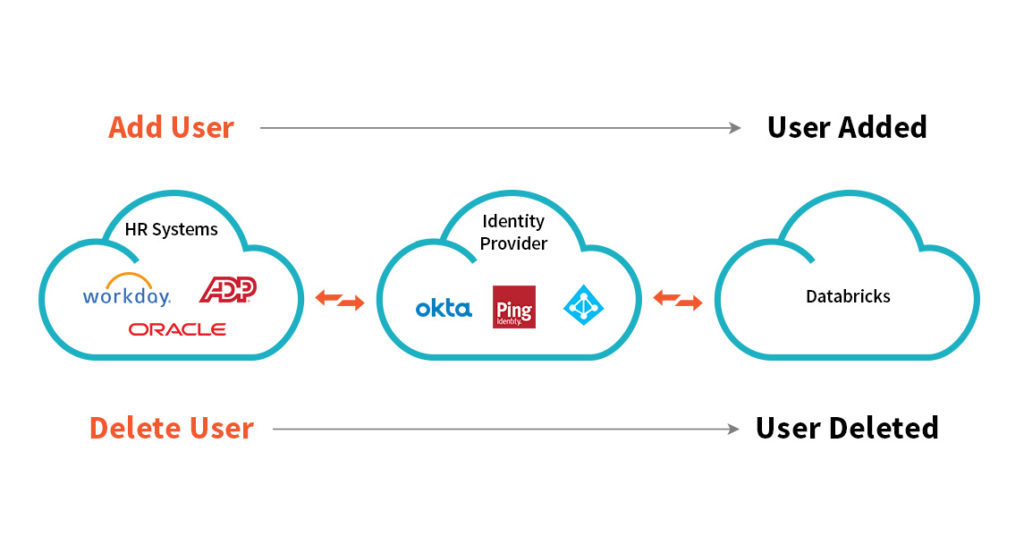
SCIM API: Native support for System for Cross-domain Identity Management (SCIM) allows customers to automatically onboard and off-board users.
Clusters and Jobs APIs: Deploy thousands of clusters and jobs at scale reliably and consistently backed by a massive scale, low-latency API endpoint.
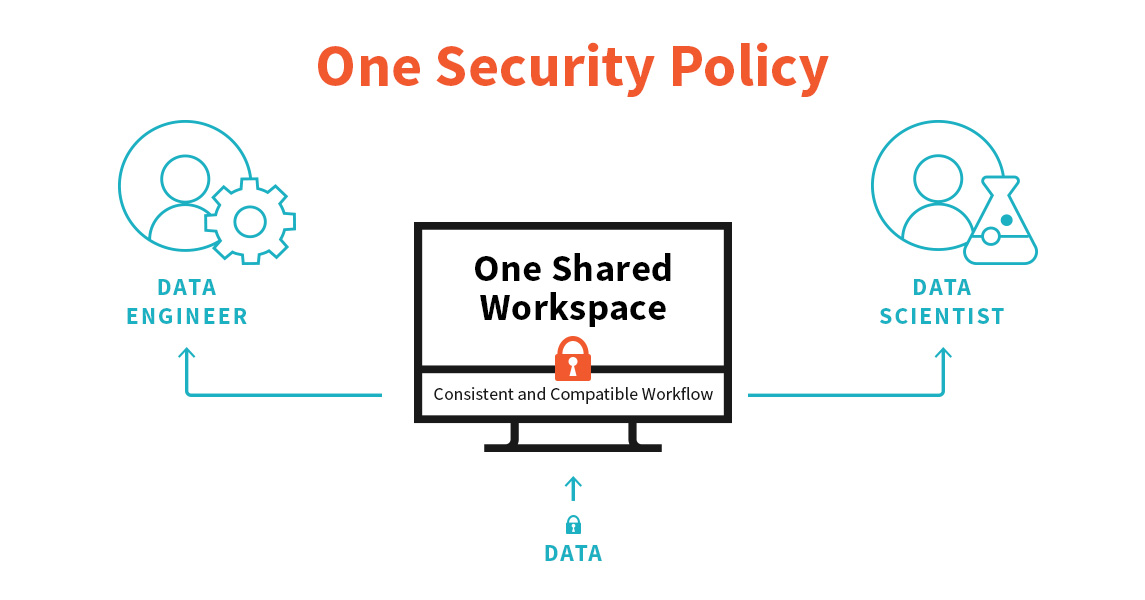
Multiple Workspaces: Quickly spin up 1000’s of new workspaces as needed in the same account with the right access and security policies applied. You can manage the workspace using the workspace UI, the Databricks CLI, and the Databricks REST API.
EASY DEVOPS
APIs: Databricks takes an API first approach to building features on the platform. With each feature, the APIs are built first before a UI is developed.
STREAMLINE OPERATIONS
Monitoring: Integrate easily with monitoring apps to view real-time metrics, application and infrastructure logs.
Auto-Scaling: Databricks clusters spin-up and scale for processing massive amounts of data when needed and spin down when not in use.
Pools: Enable clusters to start and scale faster by creating a managed cache of virtual machine instances that can be acquired for use when needed.
Regions: Databricks is available in various regions around the world on Azure and AWS
Testimonials
“With simplified administration and governance, Databricks’ Unified Data Analytics Platform has allowed us to bring data-based decision making to teams across our organization. The ease of adding users, native security integrations with cloud providers and APIs-for-everything have enabled us to bring the data and tools we need, to every employee in Wehkamp,”
– Tom Mulder, Lead Data Scientist at Wehkamp.
Documentation
Test the platform for yourself
Start your free trial
Use the Quick Start Guide to get the most out of your 14 day free trial
Resources