Machine Learning Runtime
Ready-to-use and optimized machine learning environment
The Machine Learning Runtime (MLR) provides data scientists and ML practitioners with scalable clusters that include popular frameworks, built-in AutoML and optimizations for unmatched performance.
Benefits

FRAMEWORKS OF CHOICE
ML Frameworks are evolving at a frenetic pace and practitioners need to manage on average 8 libraries. The ML Runtime provides one-click access to a reliable and performant distribution of the most popular ML frameworks, and custom ML environments via pre-built containers or Conda.
AUGMENTED MACHINE LEARNING
Accelerate machine learning from data prep to inference with built-in AutoML capabilities including hyperparameter tuning and model search using Hyperopt and MLflow.
SIMPLIFIED SCALING
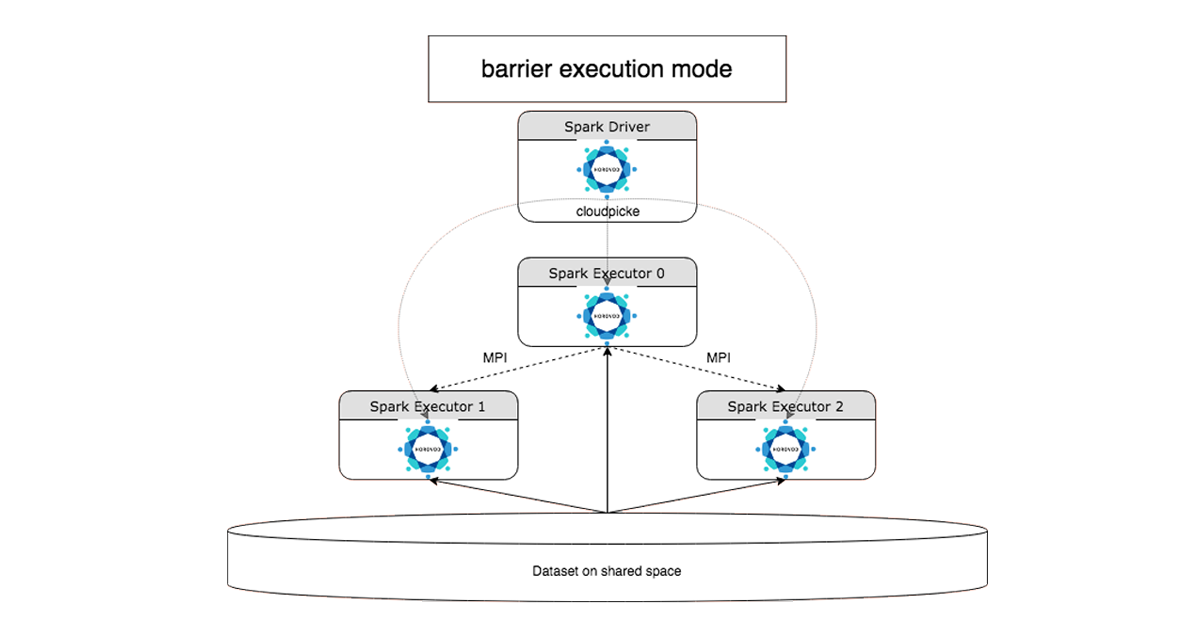
Go from small to big data effortlessly with an auto-managed and scalable cluster infrastructure. The Machine Learning Runtime also includes unique performance improvements for the most popular algorithms as well as HorovodRunner, a simple API for distributed deep learning.
Features
FRAMEWORKS OF CHOICE
ML Frameworks: The most popular ML libraries and frameworks are provided out-of-the-box including TensorFlow, Keras, PyTorch, MLflow, Horovod, GraphFrames, scikit-learn, XGboost, numpy, MLeap, and Pandas.
AUGMENTED ML
Automated Experiments Tracking: Track, compare, and visualize hundreds of thousands of experiments using open source or Managed MLflow and the parallel coordinates plot feature.
Automated Model Search (for Single-node ML): Optimized and distributed conditional hyperparameter search across multiple model architectures with enhanced Hyperopt and automated tracking to MLflow.
Automated Hyperparameter Tuning for Single-node Machine Learning: Optimized and distributed hyperparameter search with enhanced Hyperopt and automated tracking to MLflow.
Automated Hyperparameter Tuning for Distributed Machine Learning: Deep integration with PySpark MLlib’s Cross Validation to automatically track MLlib experiments in MLflow.
OPTIMIZED FOR SIMPLIFIED SCALING
Optimized TensorFlow: Benefit from TensorFlow CUDA-optimized version on GPU clusters for maximum performance.
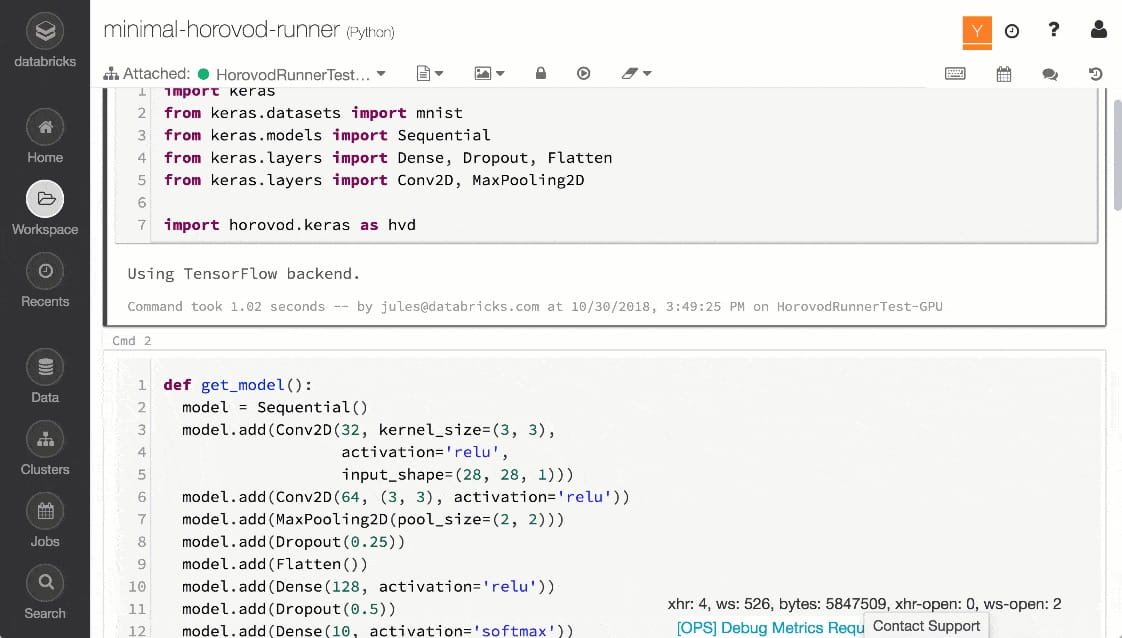
HorovodRunner: Quickly migrate your single node deep learning training code to run on a Databricks cluster with HorovodRunner, a simple API that abstracts complications faced when using Horovod for distributed training.
Optimized MLlib Logistic Regression and Tree Classifiers: The most popular estimators have been optimized as part of the Databricks Runtime for ML to provide you with up to 40% speed-up compared to Apache Spark 2.4.0.
Optimized GraphFrames: Run GraphFrames 2-4 times faster and benefit from up to 100 times speed-up for Graph queries, depending on the workloads and data skew.
Optimized Storage for Deep Learning Workloads: Leverage high-performance solutions on Azure & AWS for data loading and model checkpointing, both of which are critical to deep learning training workloads.
How It Works
The Machine Learning Runtime is built on top and updated with every Databricks Runtime release. It is generally available across all Databricks product offerings including: Azure Databricks, AWS cloud, GPU clusters and CPU clusters.
To use the ML Runtime, simply select the ML version of the runtime when you create your cluster.
Customer Stories
![]()
Watch the Spark+AI Summit Talk
Simplify Distributed TensorFlow Training for Fast Image Categorization at Starbucks

Ready to get started?
Resources



Webinars
MLOps Virtual Event