

Delta Live Tables (DLT) makes it easy to build and manage reliable data pipelines that deliver high quality data on Delta Lake. DLT helps data engineering teams simplify ETL development and management with declarative pipeline development, automatic data testing, and deep visibility for monitoring and recovery.
More easily build and maintain data pipelines
With Delta Live Tables, easily define end-to-end data pipelines by specifying the data source, the transformation logic, and destination state of the data — instead of manually stitching together siloed data processing jobs. Automatically maintain all data dependencies across the pipeline and reuse ETL pipelines with environment independent data management. Run in batch or streaming and specify incremental or complete computation for each table.
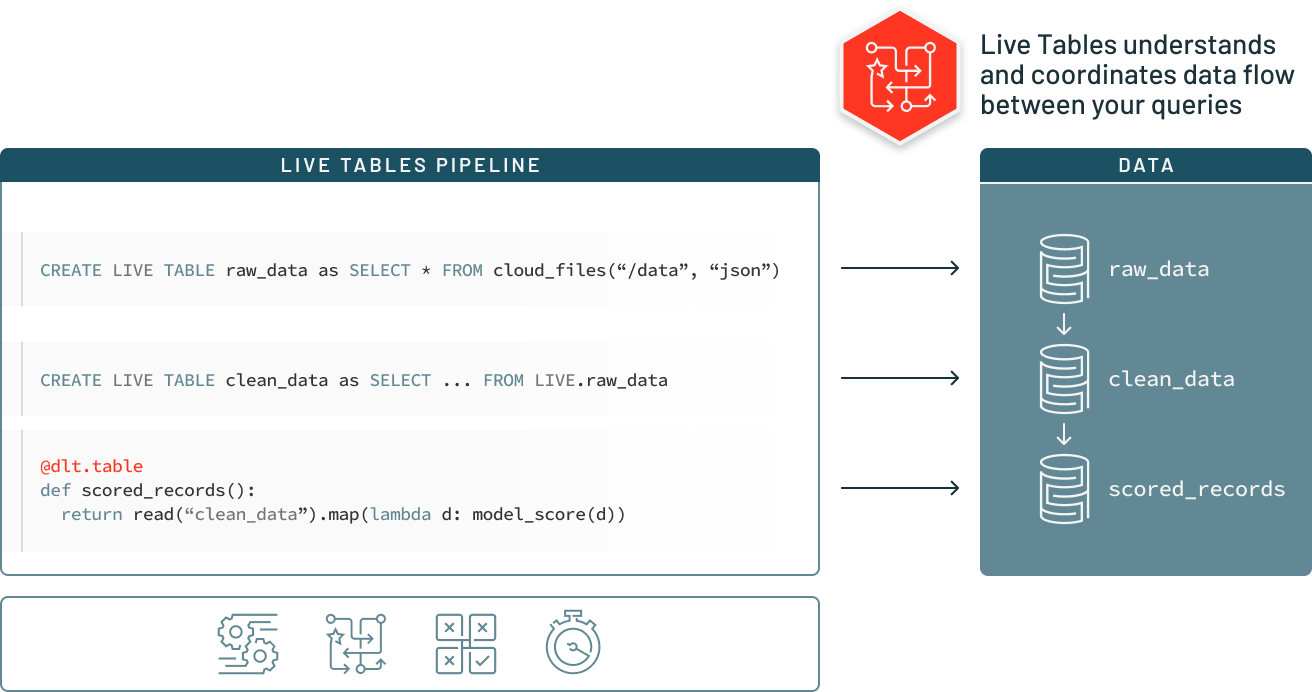
Automatic Testing
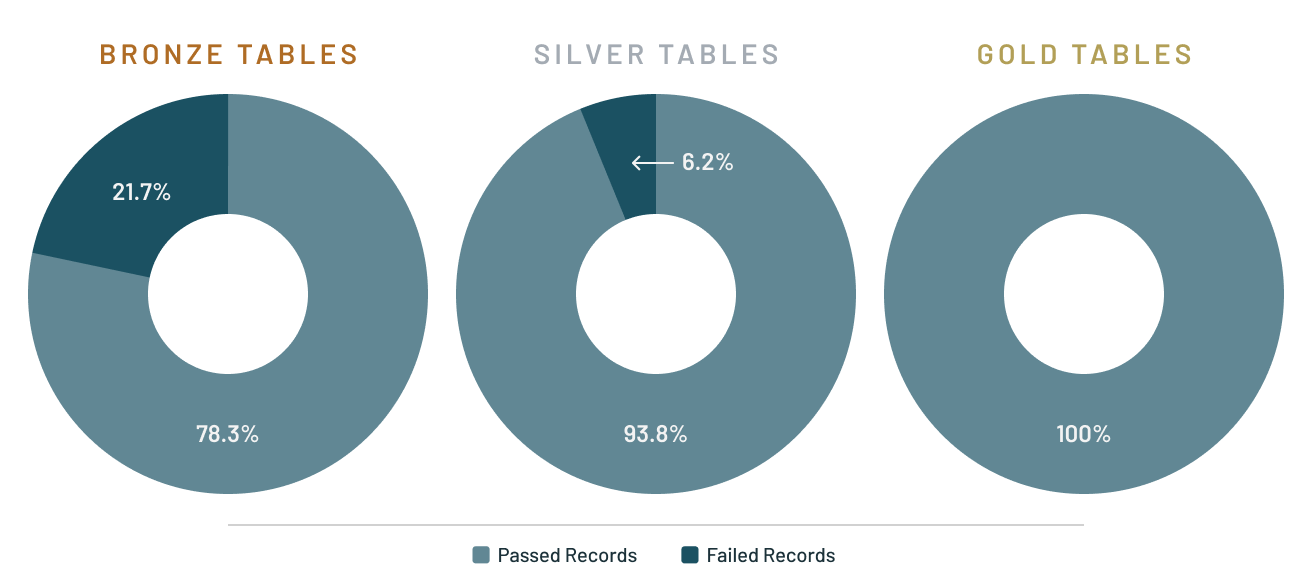
Delta Live Tables helps to ensure accurate and useful BI, data science and machine learning with high-quality data for downstream users. Prevent bad data from flowing into tables through validation and integrity checks and avoid data quality errors with predefined error policies (fail, drop, alert or quarantine data). In addition, you can monitor data quality trends over time to get insight into how your data is evolving and where changes may be necessary.
Deep visibility for monitoring and easy recovery
Gain deep visibility into pipeline operations with tools to visually track operational stats and data lineage. Reduce downtime with automatic error handling and easy replay. Speed up maintenance with single-click deployment and upgrades.
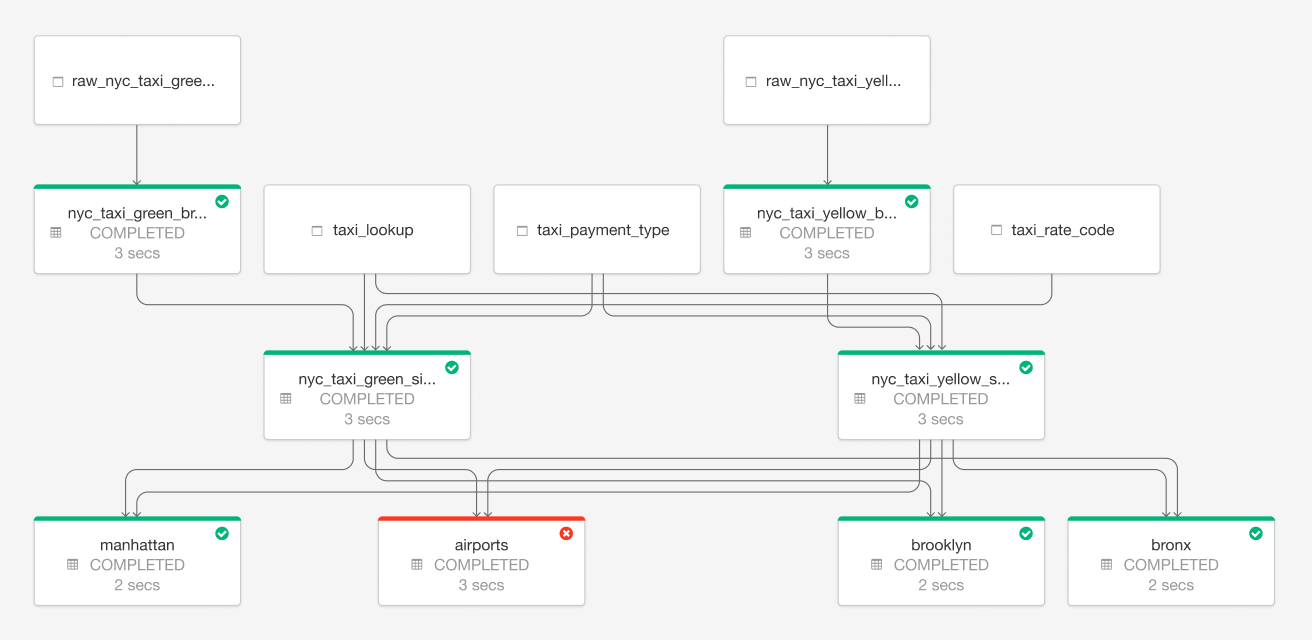
Use Cases
![]()
Meet regulatory requirements
Capture all information about your table for analysis and auditing automatically with the event log. Understand how data flows through your organization and meet compliance requirements.
![]()
Simplify data pipeline deployment and testing
With different copies of data isolated and updated through a single code base, data lineage information can be captured and used to keep data fresh anywhere. So the same set of query definitions can be run in development, staging and production.

Reduce operational complexity with unified batch and streaming
Build and run both batch and streaming pipelines in one place with controllable and automated refresh settings, saving time and reducing operational complexity.
Customer Success Stories


CUSTOMER STORY
Moving to the cloud ushers in a new era of data-driven retail
Moving to the cloud ushers in
a new era of data-driven retail

CUSTOMER STORY
Putting patients' health first with data and AI
Putting patients' health first
with data and AI
At Shell, we are aggregating all our sensor data into an integrated data store. Delta Live Tables has helped our teams save time and effort in managing data at [the multi-trillion-record scale] and continuously improving our AI engineering capability.With this capability augmenting the existing lakehouse architecture, Databricks is disrupting the ETL and data warehouse markets, which is important for companies like ours. We are excited to continue to work with Databricks as an innovation partner.
– Dan Jeavons, General Manager – Data Science, Shell



