
The Databricks Administration guide addresses how to set up Databricks on AWS, walking through the implementation of features like tagging, groups and secrets. Here are some considerations and decision points to help you understand the trade-offs of implementation decisions. Many of these items are examined in more detail in the Enterprise rollout on AWS datasheet.
Data platform management strategies
Distributed vs. centralized
![]()
Distributed strategy
The distributed strategy allows for separate teams to have their own environments:
- They can be granted admin rights to that workspace for cluster and resource creation
- They don’t have to worry about constraining or contradicting other teams
- The workspace access stays locked down to the specific team members granted access to the specific workspace
![]()
Centralized strategy
On the other hand, a centralized strategy allows:
- More flexibility with cross-team communication and knowledge sharing
- A single source of truth
- Allows more specific components of the workspace to be locked down to restrict resources from being open to all users
![]()
Best practice
Using the E2 version of Databricks with a distributed model — one account maintained by the admin team, while each team utilizes Databricks with two workspaces: Production and Development for individualized workflows.
E2 vs. non-E2 (single tenant)
The E2 version of the Databricks platform (released in September 2020) makes the Databricks platform on AWS more secure, scalable and simpler to manage. E2’s architecture provides:
![]()
Multi-workspace accounts
Create multiple workspaces per account using the Account API. The workspaces are linked by a single account, so that all workspace configurations can be managed by a central team while allowing more admin rights to the individual teams per each workspace. A chargeback can be set up and distributed to each of the individual workspaces (teams) and still seen in an aggregated view in the Account API.
![]()
Customer-managed VPCs
Create Databricks workspaces in your own VPC rather than using the default architecture in which clusters are created in a single AWS VPC that Databricks creates and configures in your AWS account.
![]()
Secure cluster connectivity
Also known as “No Public IPs,” secure cluster connectivity lets you launch clusters in which all nodes have only private IP addresses, providing enhanced security.
![]()
Customer-managed keys for notebooks
(Public Preview): Provide KMS keys to encrypt notebooks in the Databricks-managed control plane.
Common roles and personas
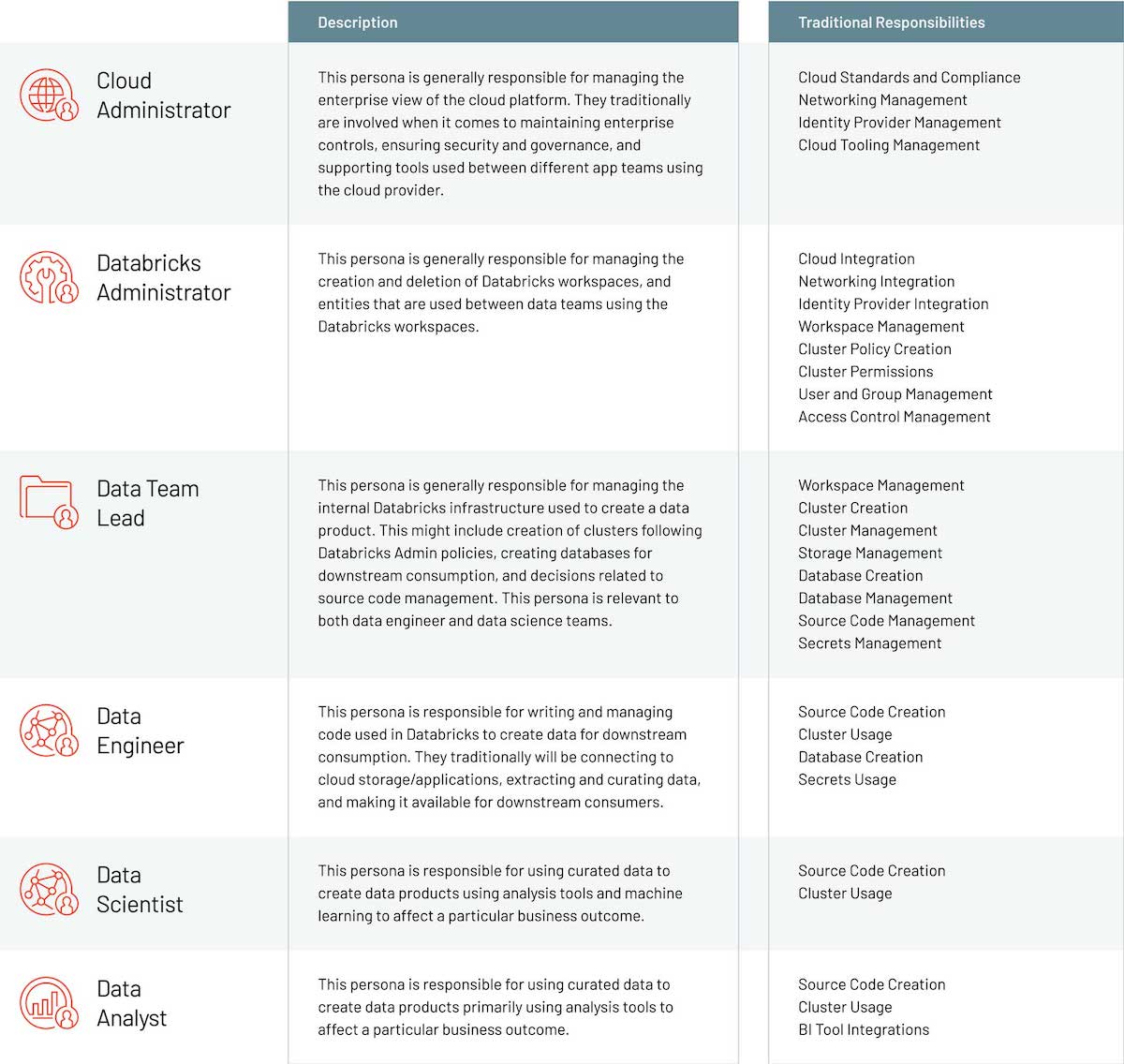
Cloud platform
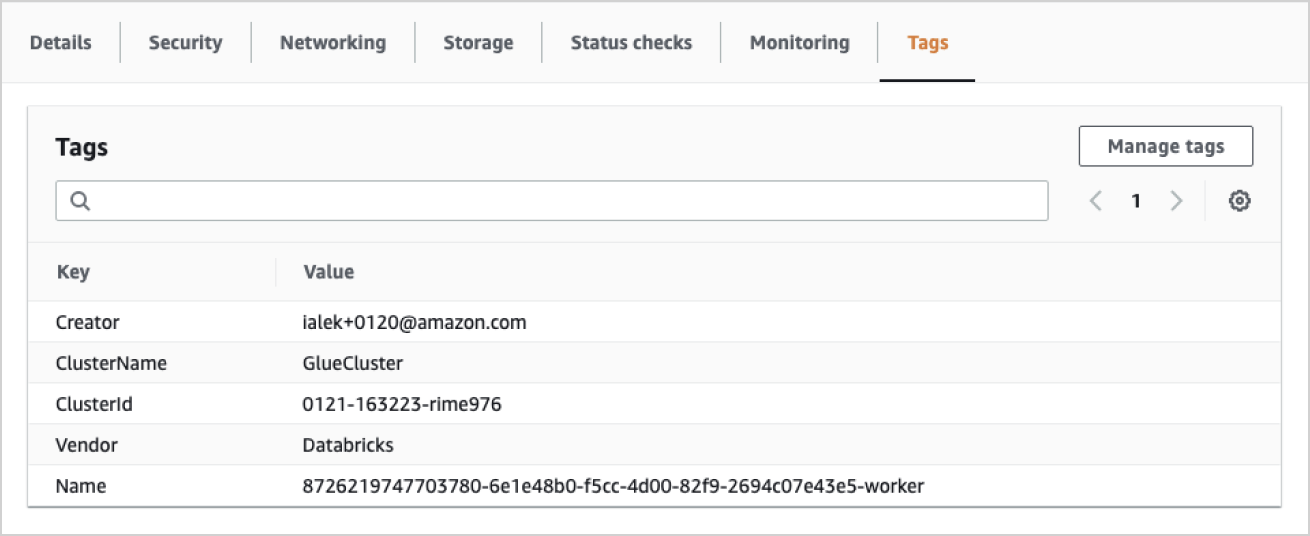
Tagging cloud assets
AWS allows you to “tag” Databricks clusters, which have a variety of different usages. These tags can be used to enforce compliance, chargeback between departments, and monitoring cloud assets in a consistent and coherent fashion by the cloud administrator. These tagging requirements can be introduced by the cloud administrator, Databricks administrator, or even data team leads.
The tags should be consistent and applicable across all teams and enforced by the admin team to make sure resource costs and analysis can be allocated properly. Here are some common questions teams must address to prepare for this implementation.
- Is there an enterprise tagging schema to implement?
- Is there a tagging schema specific to Databricks to implement?
- Is there a tagging schema specific to the Databricks workspace in which we are operating in?
- Is there a tagging schema specific to our data team?
You can read more about this in the Databricks documentation.
External Apache Hive metastore
Databricks workspaces natively integrate a Hive metastore, which is used to track schema, location and additional metadata about data stored remotely in the cloud. One challenge that customers experience is maintaining a consistent vision of these data assets across the enterprise, as each workspace has its own definition.
Depending on your organization’s goals, consider rolling your own external Hive metastore, as this will allow enterprises to share a common metadata repository between Databricks workspaces.
This configuration is not officially supported by Databricks however, so the client assumes risk in operating and maintaining the RDBMS that supports the Hive metastore. This also comes at the added cost of running a RDBMS instance in perpetuity in a cloud environment and ensuring that your enterprise networking
strategy allows for centralized access to this resource.
Databricks can also integrate with AWS Glue as a metastore.
You can learn more on the Databricks Catalog page.
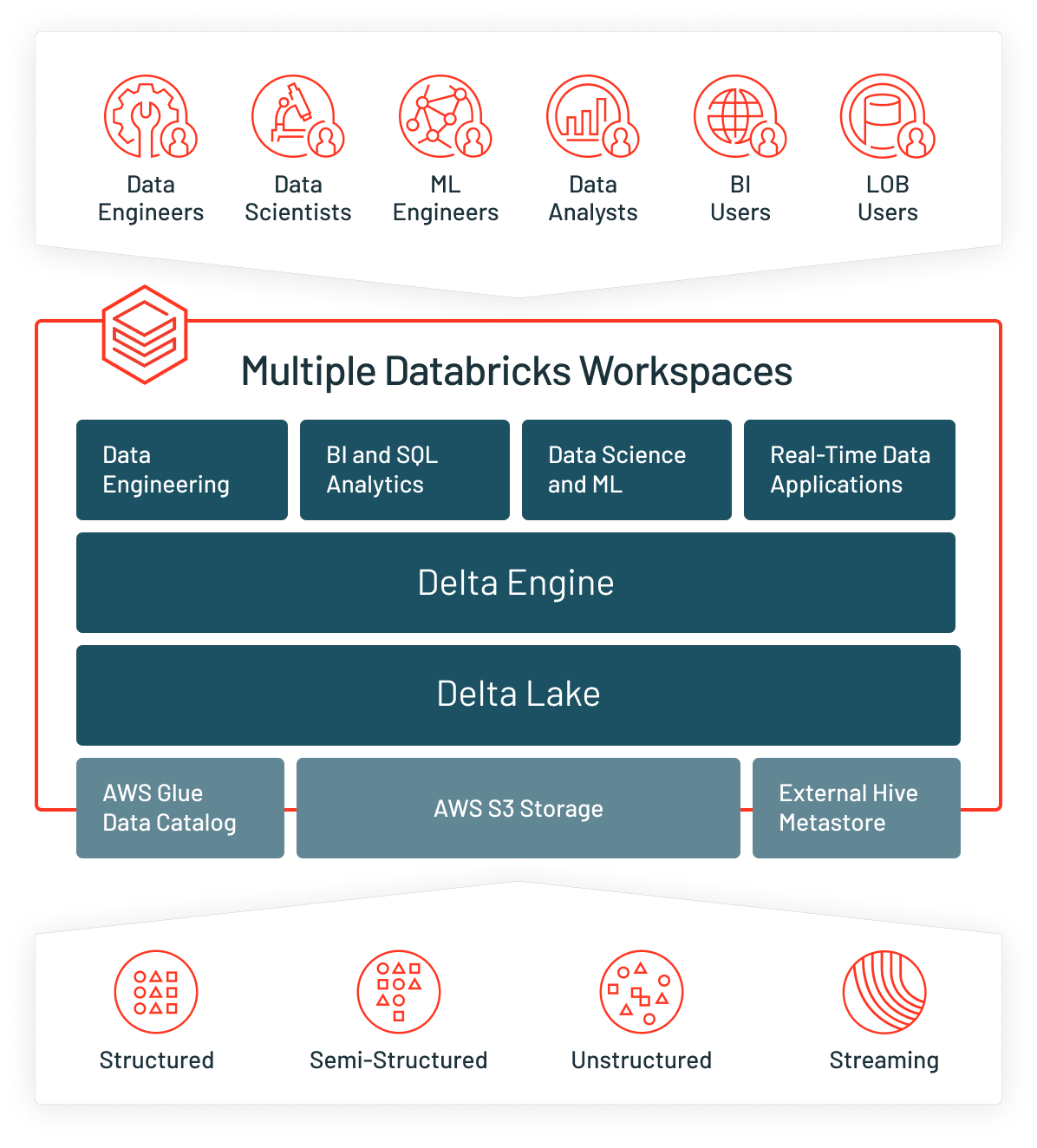
Cloud provider — AWS
AWS account
management
When selecting AWS as your cloud provider, the first thing you will need is an AWS account. Databricks will create assets inside of your AWS account and, when you use the Databricks Web Application, all Spark/SQL commands will be sent from the Databricks “Control Plane” to the assets in your AWS account, known as the “Data Plane.”
Enterprises have different requirements around account administration, where some enterprises will use the same AWS account, and some organizations will use different AWS accounts based on business requirements. Segregating Databricks workspaces into different AWS accounts allows for greater segregation of responsibility, yet increases operational overhead when attempting to work between AWS accounts.
Certain resources are limited based on the account provisioned (for example, there is a single AWS Glue data catalog available that correlates with the AWS account). Reviewing these limitations, considering the enterprise standards and controls for creating cloud infrastructure, and ensuring that your Databricks provisioning strategy is aligned are critical to successful enterprise adoption.
Databricks
account admin
When creating a Databricks workspace, you associate your AWS account with your Databricks account using the Accounts API. The account admin is the single source for all Databricks workspaces running across your enterprise. Account administration may be delegated to the cloud administrator or to the Databricks administrator, depending on roles/responsibilities inside your enterprise. It is a preferred best practice to have a single Databricks account for your enterprise, such that you can holistically look at the costs associated with using Databricks in a single location, instead of having to piece this information together from several different accounts.
Databricks
cross-account role
Databricks needs access to a cross-account service IAM role in your AWS account so that Databricks can deploy clusters in the appropriate VPC for the new workspace. The Databricks Account API supports multiple credentials, so it is easy to configure a cross-account role for each workspace, which allows for greater flexibility and auditability moving forward. Some customers choose to use only one cross-account role for all their Databricks workspaces to simplify workspace creation, which is another entirely acceptable solution.
AWS root bucket
The root storage S3 bucket in your account is required to store objects like cluster logs, notebook revisions and job results. You can also use the root storage S3 bucket for storage of non-production data, like data you need for testing. You can share a root S3 bucket with multiple workspaces in a single account. You do not have to create new ones for each workspace. If you share a root S3 bucket for multiple workspaces in an account, data on the root S3 bucket is partitioned into separate directories by workspace. Some enterprises prefer to entirely separate the operation of each workspace by creating a dedicated bucket for each workspace, while other enterprises prefer to consolidate and manage a single S3 bucket across all workspaces. The recommended best practice is to have the S3 bucket in the same AWS region as the workspace, so if your enterprise prefers to centralize infrastructure, it is recommended to have a centralized S3 bucket for each AWS region instead of configuring storage in a different region.
AWS networking
security
Databricks-managed VPC
By default, Databricks creates a VPC in your AWS account for each workspace. Databricks uses it for running clusters in the workspace. When Databricks creates the VPC during workspace creation, the lifecycle of the VPC is tied to the lifecycle of the workspace. This may be desired as the networking infrastructure will clean itself up as part of deleting the workspace. This may not be ideal for customers who have specific networking requirements however, or would like to co-locate services inside of the Databricks VPC.
Customer-managed VPC
Optionally, you can use your own VPC for the workspace, using the feature Customer-Managed VPC. Databricks recommends that you provide your own VPC so that you can configure it according to your organization’s enterprise cloud standards while still conforming to Databricks requirements. You cannot migrate an existing workspace to your own VPC.
There is more documentation available here
AWS data security
Databricks supports Access Control lists all the way down to the storage layer. Databricks can take advantage of its cloud backbone by utilizing state-of-the-art AWS security services right in the platform. Federate your existing AWS data access roles with your identity provider via SSO to simplify managing your users and their secure access to the data lake. Databricks can also leverage the power of AWS CloudTrail and CloudWatch to provide data access information across your deployment account and any others you configure.
IAM instance profiles
An IAM role is an AWS identity with permission policies that determine what the identity can and cannot do in AWS. An instance profile is a container for an IAM role that you can use to pass the role information to an EC2 instance when the instance starts.
In order to access AWS resources securely, you can launch Databricks clusters with instance profiles that allow you to access your data from Databricks clusters without having to embed your AWS keys in notebooks. This article explains how to set up instance profiles and use them in Databricks to access S3 buckets securely.
Using credential pass-through
IAM credential pass-through allows you to authenticate automatically to S3 buckets from Databricks clusters using the identity that you use to log in to Databricks. When you enable your cluster for IAM credential pass-through, commands that you run on that cluster can read and write data in S3 using your identity. IAM credential pass-through has two key benefits over securing access to S3 buckets using instance profiles:
- IAM credential pass-through allows multiple users with different data access policies to share one Databricks cluster to access data in S3 while always maintaining data security. An instance profile can be associated with only one IAM role. This requires all users on a Databricks cluster to share that role and the data access policies of that role.
- IAM credential pass-through associates a user with an identity. This in turn enables S3 object logging via CloudTrail. All S3 access is tied directly to the user via the ARN in CloudTrail logs.
In AWS, leveraging credential pass-through is the preferred authentication/authorization method for accessing data for the reasons listed above. Credential pass-through does, however, have known limitations, which are listed in the documentation section below. The workaround for using credential pass-through is to directly use the Instance Profile, instead of configuring a Meta Instance Profile and then assuming the role. This unfortunately will not propagate the user’s identification to the underlying AWS infrastructure however, so it’s recommended to use this method only when encountering one of the documented limitations.
For more information, read Deliver and Access Billable Usage Logs and Monitor Your Databricks Workspace With Audit Logs.