
Explainable AI
Ensure your ML models are transparent, trustworthy and understandable
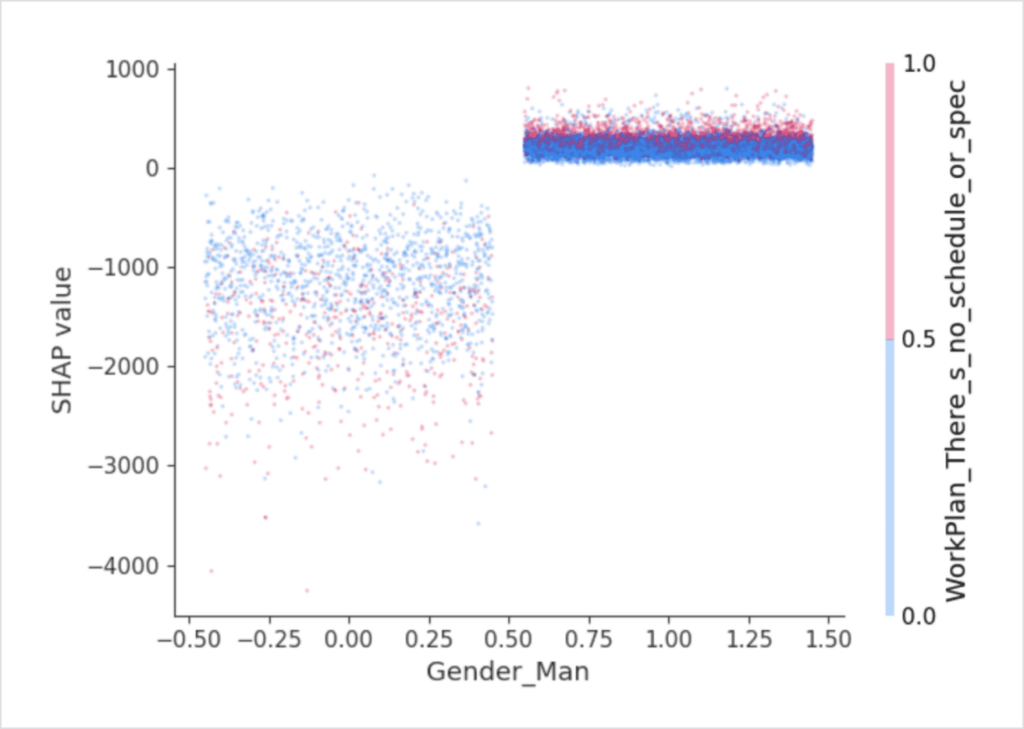
Detect bias early in your model lifecycle
Your model is only as good as your data, and explainability solutions can help you detect, analyze and find evidence of bias early on in your ML projects. Databricks Machine Learning integrates with SHAP to augment your models with explanations and identify overweight inputs and oddities in your data.
Build on an open foundation for complete transparency
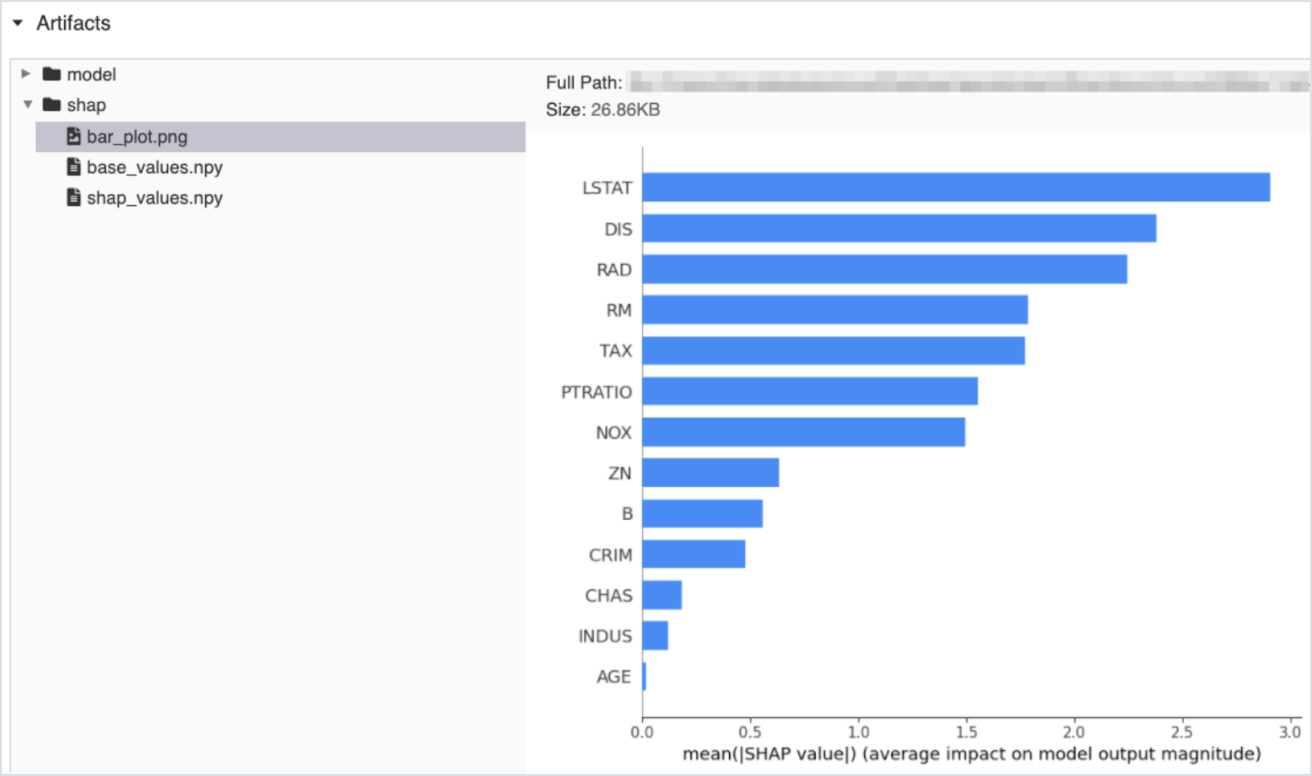
The explainability capabilities of Databricks Machine Learning are open and built natively on MLflow. The SHAP module computes and logs the relative importance of features impacting a model’s output, and resulting explanations can be delivered visually through feature importance graphs or numerically through SHAP values. The SHAP module can also create and log explainer objects that delineate the feature importance of individual outputs of models in production.
Provide end-to-end visibility into your models
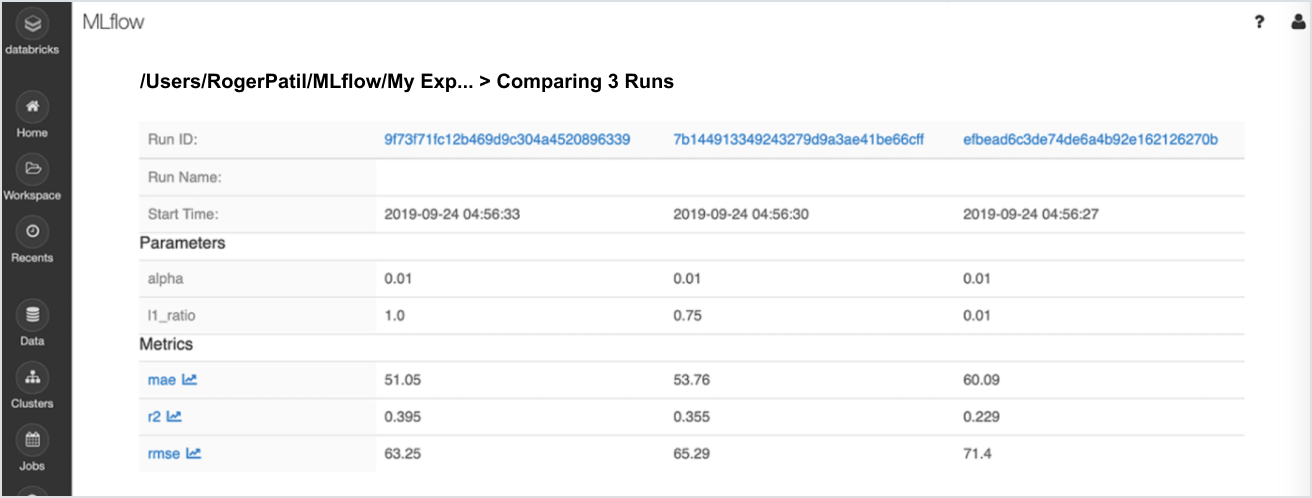
Model explainability is only useful if you also have data explainability. If your model is not performing as expected (or is biased), most often this is due to the underlying data. Databricks supports full lineage tracking that connects a model, along with its explanations, with the data set that was used to train it, as well as metrics parameters. Bias can be logged, monitored and remedied at each stage of the model lifecycle.
Build responsibility and fairness into your AI
The interpretability of your models has a large impact on customer, shareholder and employee trust, and helps you ensure compliance with regulatory and ethical guidelines. Whether it’s explainable NLP in the medical services industry or evaluating the gender pay gap in tech, discover the many use cases and customers powered by Explainable AI from Databricks.

