Getting Started with Delta Lake
Tech Talk Series
Overview
The rise of the Lakehouse architectural pattern is built upon tech innovations enabling the data lake to support ACID transactions and other features of traditional data warehouse workloads. Join us for a five-part learning series on Getting Started with Delta Lake. This series of tech talks takes you through the technology foundation of Delta Lake (Apache Spark), building highly scalable data pipelines, tackling merged streaming + batch workloads, powering data science with Delta Lake and MLflow and even goes behind the scenes with Delta Lake engineers to understand the origins.
Many of the workshops include notebooks and links to slides for you to download.
If you’d like to follow along, please Sign Up for your free Community Edition account or download the Delta Lake library.

Making Apache Spark Better with Delta Lake
Apache Spark is the dominant processing framework for big data. Delta Lake adds reliability to Spark so your analytics and machine learning initiatives have ready access to quality, reliable data. This webinar covers the use of Delta Lake to enhance data reliability for Spark environments.

Simplify and Scale Data Engineering Pipelines
A common data engineering pipeline architecture uses tables that correspond to different quality levels, progressively adding structure to the data: data ingestion (“Bronze” tables), transformation/feature engineering (“Silver” tables), and machine learning training or prediction (“Gold” tables). Combined, we refer to these tables as a “multi-hop” architecture. It allows data engineers to build a pipeline that begins with raw data as a “single source of truth” from which everything flows.
Beyond Lambda: Introducing Delta Architecture
Lambda architecture is a popular technique where records are processed by a batch system and streaming system in parallel. The results are then combined during query time to provide a complete answer. With the advent of Delta Lake, we are seeing a lot of our customers adopting a simple continuous data flow model to process data as it arrives. We call this architecture the “Delta Architecture.” In this session, we cover the major bottlenecks for adopting a continuous data flow model and how the Delta Architecture solves those problems.
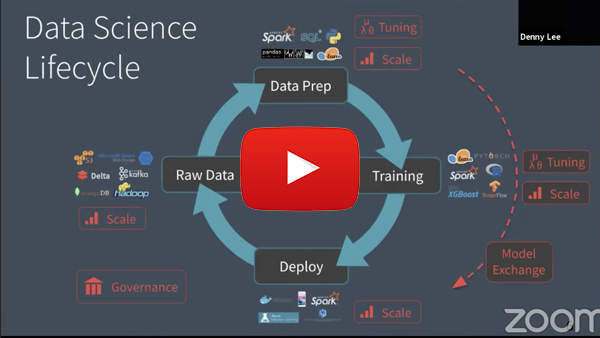
Getting Data Ready for Data Science with Delta Lake and MLflow
One must take a holistic view of the entire data analytics realm when it comes to planning for data science initiatives. Data engineering is a key enabler of data science helping furnish reliable, quality data in a timely fashion. Delta Lake, an open-source storage layer that brings reliability to data lakes can help take your data reliability to the next level.

Behind the Scenes: Genesis of Delta Lake
Developer Advocate Denny Lee interviews Burak Yavuz, Software Engineer at Databricks, to learn about the Delta Lake team’s decision making process and why they designed, architected, and implemented the architecture that it is today. Understand technical challenges that the team faced, how those challenges were solved, and learn about the plans for the future.

Next Up: Diving Into Delta Lake
Dive through the internals of Delta Lake, a popular open source technology enabling ACID transactions, time travel, schema enforcement and more on top of your data lakes.